It is common practice in many networking libraries in many languages to spawn threads to handle asynchronous communications in the background while the rest of the program continues to function. Although this approach does work on the iPhone, it's really not the right way to do it. I've recently run across two different blog postings that show how to download images for display in an iPhone table view, and they both did synchronous network communications using threads.
Here's my Public Service Announcement for today: Don't. Please… just, please don't, okay? Don't spawn threads for asynchronous communications unless
you would have used threads in the same situation if there was no network code..
Note: A few people have suggested that this post is misleading because threads are used behind the scenes. Yes, it is true that the iPhone OS will spawn a small number of non-main threads as the result of using certain networking APIs. You still should be using the asynchronous APIs for your network communications and should not be spawning threads so you can make synchronous networking calls without blocking.
I don't like to knock other people's tutorials. In programming, there are multiple ways of doing nearly everything, and often more than one approach has merit in certain situations, so I'm always hesitant to say that the approach someone else uses is "wrong" if it works. But, this is one of those cases where there is a clear and compelling reason not to do it one particular way. However, because the "right" way is not necessarily intuitive, especially for people whose networking experience has all been thread-based, I thought it worth a short tutorial to show how to download asynchronously for display in a table without spawning any threads.
But first, why shouldn't we use threads this way? Well, simply put, threads have overhead. It's not a huge overhead, but it's non-zero and, in fact, it's non-trivial given the processing power and physical memory available on iPhone OS devices. The overhead of threading absoulutely makes sense in some situations; asynchronous networking is not one of those situations. Apple provides asynchronous APIs specifically for this purpose and they're designed to give the best performance in light of available system resources.
But, don't take my word for it. Here is what
Apple says on the matter, in a guide written to help Windows programmers make the transition to programming for the Mac (
emphasis mine):
One of the complexities of socket use involves the use of separate threads to handle the exchange of data. In a server environment, where hundreds of sockets are open simultaneously, the code that checks all these threads for activity may cause a significant performance hit. In addition, with threads, data synchronization is often an issue, and locks are often required to guarantee that only one thread has access to a given global variable at a time.
[...]
Event-driven code is more complex than code using blocking threads, but it delivers the highest network performance. When you use a run loop to handle multiple sockets in the same thread, you avoid the data synchronization problems associated with a multiple-thread solution.
When Apple says something as specific as this, they usually have a darn good reason for it. This is Apple's polite way of saying "don't use threads for networking, you idiot". They're a lot more polite than I am, obviously.
As you probably know, your application's main thread (the one that gets created automatically when your application is launched) has a loop (contained in
UIApplication) that's always running. It's called your application's
run loop and it keeps running as long as your application is executing. Every time through this loop,
UIApplication does a whole bunch of stuff. It checks for inputs from the hardware and mach messages from the OS, for example, and it looks to see if there are any
NSTimers running whose targets need to be called. Among the tasks it does is to check for incoming network data. There are more things the run loop handles, but that last one is the important for today's discussion.
Conceptually speaking, CFNetwork is not the easiest framework to grasp, but it is extremely efficient. It can handle hundreds, maybe even thousands of simultaneous downloads without causing the main thread to seize up. It's considerably more efficient than using synchronous network calls on a thread and not really any harder once you know how to do it.
Let's Try Downloading on the Main Thread
I've written a
small iPhone app that downloads images from
Deviant Art. You just enter somebody's Deviant Art username into a text field and the application will grab the the images in that person's gallery, download them asynchronously, and display each one in the table once it's finished downloading:
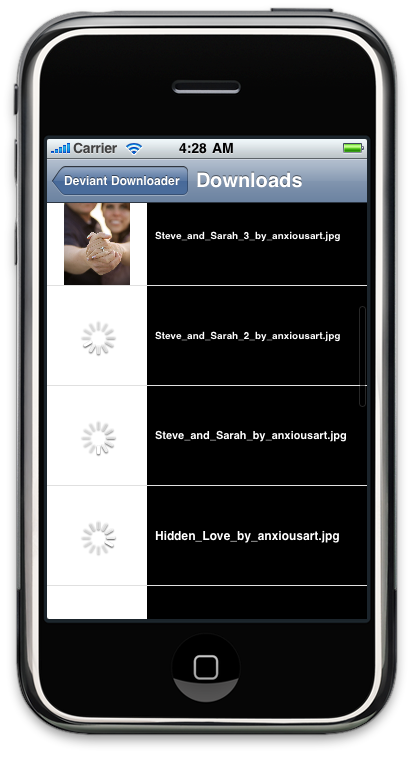
Notice that there's an activity indicator showing that some images are in the process of being downloaded. This is all happening on the main thread. I spawn no explicit threads in this application, and yet the UI stays responsive. You can also tap a row to view the image larger, but that's not really important to the process being illustrated.
Note:Although most DeviantArt galleries are SFW, there are many that aren't, so just be aware of that. Edit: Turns out that warning was unnecessary - since we haven't authenticated, DeviartArt filters out all the NSFW images automatically.
Creating the Download Object
In your own applications, you may approach things somewhat differently, but for this sample application, I'm going to put the code to download the image in its own data model class called
DeviantDownload. I'm going to override the accessor method for the image so that the first time that accessor is called, it will kick off the download. If I call the image accessor method and get
nil, the calling code can make itself the download's delegate to get notified when the download finishes.
In this application, downloads don't get triggered until the first time an image scrolls onto the screen. That may not be what you want in your application, but it will keep things nice and simple for this example. Here's the declaration of our download class:
#import <Foundation/Foundation.h>
#define DeviantDownloadErrorDomain @"Deviant Download Error Domain"
enum
{ DeviantDownloadErrorNoConnection = 1000,
};
@class DeviantDownload;
@protocol DeviantDownloadDelegate
- (void)downloadDidFinishDownloading:(DeviantDownload *)download;
- (void)download:(DeviantDownload *)download didFailWithError:(NSError *)error;
@end
@interface DeviantDownload : NSObject
{ NSString
*urlString; UIImage
*image; id <NSObject, DeviantDownloadDelegate> delegate;
@private NSMutableData
*receivedData; BOOL
downloading;
}
@property (nonatomic, retain) NSString *urlString;
@property (nonatomic, retain) UIImage *image;
@property (nonatomic, readonly) NSString *filename;
@property (nonatomic, assign) id <NSObject, DeviantDownloadDelegate> delegate;
@end
Pretty straightforward, right? I define an error domain and an error code for the one error situation our application generates (the rest come from
NSURLConnection). After that, I declare a protocol that defines the methods our delegate has to implement. There are only two: one that gets called when the download finishes successfully, and another that gets called if it fails. In the sample application, our error checking is minimal, but you will do real error checking in your apps, right? RIGHT?! Yes, you will, because that's the way you roll. In a real app, you might also add a third delegate method that to inform the delegate what percentage of the download is complete, but I'll leave that one as an exercise for the student.
Next, I declare the
DeviantDownload object, which only has four instances variables, one of which is private.
urlString is the url of the image to download,
image is the downloaded image, and
delegate is the object that wants to get notified about the status of the download. Finally,
receivedData is just a buffer to hold the downloaded data until I have it all and can create the image from it.
Okay, let's look at the implementation of our download object:
#import "DeviantDownload.h"
@interface DeviantDownload()
@property (nonatomic, retain) NSMutableData *receivedData;
@end
@implementation DeviantDownload
@synthesize urlString;
@synthesize image;
@synthesize delegate;
@synthesize receivedData;
#pragma mark -
- (UIImage *)image
{
if (image == nil && !downloading)
{
if (urlString != nil && [urlString length] > 0)
{
NSURLRequest *req = [[NSURLRequest alloc] initWithURL:[NSURL URLWithString:self.urlString]];
NSURLConnection *con = [[NSURLConnection alloc]
initWithRequest:req
delegate:self
startImmediately:NO];
[con scheduleInRunLoop:[NSRunLoop currentRunLoop]
forMode:NSRunLoopCommonModes];
[con start];
if (con)
{
NSMutableData *data = [[NSMutableData alloc] init];
self.receivedData=data;
[data release];
}
else
{
NSError *error = [NSError errorWithDomain:DeviantDownloadErrorDomain
code:DeviantDownloadErrorNoConnection
userInfo:nil];
if ([self.delegate respondsToSelector:@selector(download:didFailWithError:)])
[delegate download:self didFailWithError:error];
}
[req release];
downloading = YES;
}
}
return image;
}
- (NSString *)filename
{
return [urlString lastPathComponent];
}
- (void)dealloc
{
[urlString release];
[image release];
delegate = nil;
[receivedData release];
[super dealloc];
}
#pragma mark -
#pragma mark NSURLConnection Callbacks
- (void)connection:(NSURLConnection *)connection didReceiveResponse:(NSURLResponse *)response
{
[receivedData setLength:0];
}
- (void)connection:(NSURLConnection *)connection didReceiveData:(NSData *)data
{
[receivedData appendData:data];
}
- (void)connection:(NSURLConnection *)connection
didFailWithError:(NSError *)error
{
[connection release];
if ([delegate respondsToSelector:@selector(download:didFailWithError:)])
[delegate download:self didFailWithError:error];
}
- (void)connectionDidFinishLoading:(NSURLConnection *)connection
{
self.image = [UIImage imageWithData:receivedData];
if ([delegate respondsToSelector:@selector(downloadDidFinishDownloading:)])
[delegate downloadDidFinishDownloading:self];
[connection release];
self.receivedData = nil;
}
#pragma mark -
#pragma mark Comparison
- (NSComparisonResult)compare:(id)theOther
{
DeviantDownload *other = (DeviantDownload *)theOther;
return [self.filename compare:other.filename];
}
@end
To make memory management more readable, I first declare a property for
receivedData in a class extension. This creates a property that is accessible in my class but that isn't advertised to other classes. After that, I synthesize the four properties (three public declared in the header and one private declared in extension)
The first method I've written is an accessor for
image. Remember,
@synthesize creates an accessor and mutator
if one doesn't already exist in your code, so by providing an accessor but not a mutator,
@synthesize will create a mutator for me, but will use this method as its accessor. I don't want to download more than once, so I use the instance variable
downloading to keep track of whether I've already kicked off a download. If
image is
nil and I haven't previously kicked off a download, I kick one off asynchronously.
At the end of the method, I return
image, even though it will still be
nil until the download is complete. That's okay, that will be the calling code's indication that they should become the download's delegate.
The next method,
filename just returns the last part of
urlString, which is the filename. I don't want to display the whole URL in the table.
The
dealloc method is pretty standard stuff, so we can skip it.
The next four methods are the asynchronous callbacks for
NSURLConnection. The first,
connection:didReceiveResponse: is called when a connection is made. I set the length of
receivedData to zero here because if there's a redirect, this will get called multiple times and I want to flush out the payload from the earlier redirected connections. That extra data, when it exists, would prevent our image from being created.
connection:didReceiveData: gets called periodically during the download, whenever there's data sitting in the buffer for us. All I do here is tack the newly received data onto the end of what's already been received.
In
connection:didFailWithError:, I release the connection and notify our delegate. Because this is a data model object, I don't show an alert or anything. Dealing with the error isn't this object's responsibility. Once it reports it, its job is done; it'll let the controller figure out what to do with the error. This keeps our object firmly in the "model" component of the MVC paradigm and maximizes the chances I'll be able to reuse this object at some point.
Finally, in
connectionDidFinishLoading:, I create an image from the received data, assign it to the
image property and notify our delegate.
The last method,
compare: is implemented to let us determine if two
DeviantDownload objects represent the same file. I'll use this to look at two downloads and see if they are downloading the same file, which we don't want to do. Deviant Art uses a server farm to serve images, so the same image can have multiple URLs, but for a particular user, the filename must be unique, so I compare that.
Using the Download Object
In the table view controller, I pull down a list of the URLs for the given user. I'm not going to go into detail of the logic that does this, but in short, I asynchronously pull down JSON data for the user's gallery in chunks of 24 images, creating new
DeviantDownload objects for each one and adding them to the
NSMutableArray that drives our table. In our
tableView:cellForRowAtIndexPath:, here's what I do:
- (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath
{
DeviantDisplayCell *cell = (DeviantDisplayCell *)[tableView dequeueReusableCellWithIdentifier:[DeviantDisplayCell reuseIdentifier]];
if (cell == nil)
{
[[NSBundle mainBundle] loadNibNamed:@"DeviantDisplayCell" owner:self options:nil];
cell = loadCell;
self.loadCell = nil;
}
DeviantDownload *download = [downloads objectAtIndex:[indexPath row]];
cell.cellLabel.text = download.filename;
UIImage *cellImage = download.image;
if (cellImage == nil)
{
[cell.cellSpinner startAnimating];
download.delegate = self;
}
else
[cell.cellSpinner stopAnimating];
cell.cellImageView.image = cellImage;
return cell;
}
The first part of this method is standard table view cell stuff, but then I grab the
DeviantDownload object for the row being displayed. If the
image accessor method returns
nil, I show the cell's activity indicator (aka "spinning wait-a s-cond doohickey") and assign the controller as the delegate of the download. If the object doesn't return
nil, I make sure the activity indicator isn't animating and stick the download's image into the cell's image view. The first time this gets called for any particular row,
image will return
nil, which will trigger the download to start.
I also implement the
DeviantDownload delegate method that gets called when the download is complete:
- (void)downloadDidFinishDownloading:(DeviantDownload *)download
{
NSUInteger index = [downloads indexOfObject:download];
NSUInteger indices[] = {0, index};
NSIndexPath *path = [[NSIndexPath alloc] initWithIndexes:indices length:2];
[self.tableView reloadRowsAtIndexPaths:[NSArray arrayWithObject:path] withRowAnimation:UITableViewRowAnimationNone];
[path release];
download.delegate = nil;
}
All I do here is figure out the index of the object that I've been notified has finished download and I build an index path based on it. I then tell the table to reload that one cell's row. Doing that will trigger
tableView:cellForRowAtIndexPath: to get called again for the row that has completed and this time that method will get a valid
image and will stop the activity indicator and show the downloaded image instead.
Ta da! That's it. It's really not any harder than using threads or
NSOperationQueue once you get a feel for using the run-loop based approach.
If you want to try it out, you can download the full project
right here. As always, the code is free for use without any restrictions or limitations, I'd just ask that you don't republish it unchanged and claim credit for it.



 10:09 AM
10:09 AM
 Unknown
Unknown

 Posted in:
Posted in: 

 Well, it's the Thursday before WWDC and, as always, I'm swamped yet super-excited. The Pre-WWDC Pilgrimage is all planned. If you expressed interest, you should have received an e-mail with the details about how to pay if you want to take the bus.
Well, it's the Thursday before WWDC and, as always, I'm swamped yet super-excited. The Pre-WWDC Pilgrimage is all planned. If you expressed interest, you should have received an e-mail with the details about how to pay if you want to take the bus.




